ICTA Transliteration Engine
Transliteration software to transliterate between the three languages used in Sri Lanka, based on the most widely used and most logical words – developed for the ICT Agency of Sri Lanka (ICTA), by ScienceLand in 2009. The transliteration software can be used to transliterate as given below, taking into account the usage patterns and rules for handling names used in Sri Lanka. The issue of the spelling-variants used in local names, and how they may be transliterated to/from the three languages has been taken into consideration.
- From Sinhala to English
- From Sinhala to Tamil
- From Tamil to English
- From Tamil to Sinhala
- From English to Sinhala
- From English to Tamil
http://repository.icta.lk/TransliterationTest/
http://repository.icta.lk:80/TransliterationWebService/TransliterationService?wsdl
Font Convert – LK Domain Registry
After installing the given project folder in the web server, following home screen will be appear.
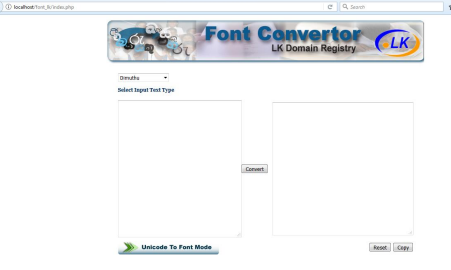
When input strings is entered and click the convert button, input string is converted to Unicode. If “Unicode to Font Mode” button is clicked and set the system to that mode, Unicode string can be inputted and convert that Unicode string to other font.
Download Files
Unicode Syntax checker
ශ්රී ලංකාව තුළ තොරතුරු සහ සන්නිවේදන තාක්ෂණය නව මගකට යොමු කරමින් මේවන විට පරිගණකය සමඟ සිංහල සහ දෙමළ බසින් කටයුතු කිරීමේ හැකියාව මුළුමුනින් ම වර්ධනය වී ඇත. යුනිකේත සම්මතය හඳුන්වාදීමත් සමඟ ඇරඹුණු මෙම නව තාක්ෂණය දේශීය භාෂා යතුරු පුවරු, විවිධ ෆොන්ට වර්ග, භාෂා සැකසුම් මෙවලම් වැනි ඒ සඳහා අවශ්ය විවිධ යටිතල පහසුකම් වර්ධනය වීම තුළ ස්ථාවර වී ඇත. මේවන විට සියළුම පරිගණක මෙහෙයුම් පද්ධති තුළ සාර්ථකව ක්රියාත්මක වන මෙම නව තාක්ෂණය හේතුවෙන් පරිගණකය තුළ සිංහල සහ දෙමළ බසින් ඇති අන්තර්ගතය ඉතා විශාල වශයෙන් වර්ධනය වී තිබේ. සබැඳි පුවත්පත්, විවිධ වෙබ් අඩවි සහ බ්ලොග් අඩවි, විකිපීඩියා සහ සමාජ ජාල වැනි විවිධ මාධ්ය හරහා ඉතා සීඝ්රයෙන් වර්ධනය වන මෙම දේශීය භාෂා අන්තර්ගතය හේතුවෙන් වර්තමානයේ දී ඉතා පහසුවෙන් අවශ්ය ඕනෑම තොරතුරක් සිංහල සහ දෙමළ බසින් සොයා ගැනීමේ සහ නැවත සැකසීමේ පහසුකම සිංහල සහ දෙමළ පරිශීලකයන්ට ලැබී ඇත.
කෙසේ වෙතත්, මෙම තොරතුරු සෙවීමේ සහ නැවත සැකසීමේ පහසුකම් ලබා ගැනීම සඳහා ඔබ නිපදවන අන්තර්ගතය සම්මත යුනිකේත ක්රමයට නිවැරදිව යතුරුලියනය කර තිබීම අත්යාවශ්ය වෙයි. විවිධ වචන සැකසුම් මෘදුකාංග ඇසුරින් ඔබ නිපදවන අන්තර්ගතය පරිගණක තිරයේ නිවැරදි ලෙස දිස්වූවත් පරිගණකය තුළ එය නිරූපණය වී ඇති කේත අනුපිළිවල නිවැරදි නොවීමට ඉඩ තිබේ. එහි එක් ප්රතිඵලයක් වන්නේ ඔබ නිපදවූ අන්තර්ගතය ගූගල් වැනි සෙවුම් යන්ත්ර භාවිතයෙන් සොයා ගත නොහැකි වීමයි. එමනිසා ඔබ නිපදවන අන්තර්ගතයෙන් බොහෝ ප්රතිඵල ලබා ගැනීමට නම්, එය නිවැරදි සම්මත යුනිකේත අනුපිළිවලට තිබේ දැයි බැලීම අත්යාවශ්ය ය. ඒ සඳහා මෙම “සිංහල දෙමළ යුනිකේත අනුපිළිවල පරීක්ෂකය“ ඔබට උපකාරී වෙයි.
At present, using ICT in Sinhala and Tamil is now completely enabled, with all key operating systems and most applications supporting Unicode Sinhala and Tamil, and due to the availability of the relevant standards, Sinhala and Tamil Unicode fonts, keyboard drivers, collation algorithms and updating the Unicode site’s locale information etc.
But in spite of all these initiatives and the measures taken for enabling the use of Unicode conformant Sinhala and Tamil, very often it has been found that users still type characters incorrectly, using incorrect sequences which yield text with incorrect (“garbage”) characters.